OAuth and Spring Security
My upcoming Pro Spring Security is heavily focused on the inner workings of the Spring Security core framework and how everything fit together under the hood.
is heavily focused on the inner workings of the Spring Security core framework and how everything fit together under the hood.
And although I do cover very important providers for authentication and authorization (including LDAP, Database, CAS, OpenID, etc) I don’t cover another important provider which is OAuth. The reason it is not covered in the book is because it is not part of the core of Spring Security but instead it is part of the Spring Security extensions project. However I know OAuth is a very popular authorization protocol and I will cover it here as a complement to the information on the book.
In this Post I want to introduce you to using OAuth with Spring Security. Many of the concepts will not be straightforward to understand, and I recommend you to read the book Pro Spring Security to understand the architecture and design of Spring Security and how it works internally.
First let’s take an overall look at the OAuth 2 protocol. I won’t be talking anything about the original OAuth 1 in this post.
OAuth 2 is an authorization protocol that specifies the ways in which authorization can be granted to certain clients to access a determined set of resources.
Directly taken from the specification, we can see in the following paragraph that OAuth 2 defines a specific set of Roles interacting in the security process:
resource owner
An entity capable of granting access to a protected resource.
When the resource owner is a person, it is referred to as an end-
user.
resource server
The server hosting the protected resources, capable of accepting
and responding to protected resource requests using access tokens.
client
An application making protected resource requests on behalf of the
resource owner and with its authorization. The term client does
not imply any particular implementation characteristics (e.g.
whether the application executes on a server, a desktop, or other
devices).
authorization server
The server issuing access tokens to the client after successfully
authenticating the resource owner and obtaining authorization.
The overall interaction that happens in the protocol is also specified in the specification, and it goes something like this:

You can see the interaction between the 4 roles defined by the protocol.
The main idea to take in mind in the traditional scenario is that an application (the Client) will try to access another application’s secured resources (Resource Server) in the name of a user (Resource Owner). In order to do so, the user needs to prove its identity, and to do so it contacts the Authorization Server presenting its credentials. The Authorization Server authenticates the user and grants the client/user combination a token that can be used to access the particular resource. In many cases the Authorization Server and Resource Server live in the same place. For example if you try to access your facebook account from another application, you will get redirected to the facebook login (Authorization Server) and then you will grant certain permissions to be able to access your facebook wall (a resource in the Resource Server).
Ok, let’s see how all that fits in the Spring Security OAuth project. There will be a couple of things that don’t work exactly the way that sites like Facebook or Twitter work, but we get to that later.
I will create both a OAuth service provider (Authentication Server but also Resource Server) and a OAuth client (Client Application) The first thing I’ll do is to check out the source of the project from Github, which I normally do with open source projects.
git clone git://github.com/SpringSource/spring-security-oauth.git
Then checkout the latest stable tag with git checkout 1.0.1.RELEASE
Next we will be playing with the OAuth 2 samples that come with the project.
I build everything with the command mvn clean install -P bootstrap
We will then open the project sparklr in the samples/oauth2 folder. This project will serve as both the Authorization Server and Resource Server from our previous definitions. Sparklr is a project that offers pictures secured with OAuth.
We will also open the tonr application in the same directory. This is the OAuth client application.
Both projects are built from the previous maven build step. I took both war files and copy them to a Tomcat 7’s webapps directory that I have in my computer under the names sparklr2.war and tonr2.war. The I started Tomcat and visited the address http://localhost:8080/tonr2/. I was received by the page in the following figure:
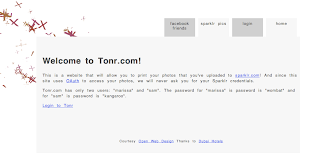
If I click in the “sparklr pics” tab I am presented with a login screen particular to the tonr application (The Client in this case has a password of its own):
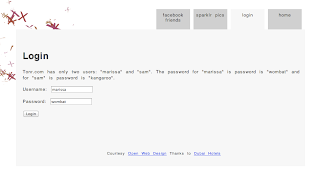
I login with the default username and password and I am redirected to the sparklr login screen now.
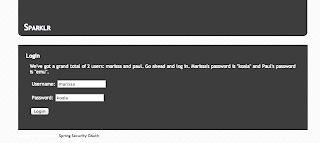
Remember this is the Authorization Server as well as the Resource Server, where the resources are pictures.
Again I login with the default username and password. This will ask for confirmation that I am allowing Tonr to access my personal resources on my behalf.
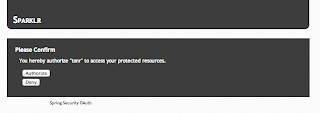
I click on Authorize. I am redirected back to Tonr and now I can see my pictures stored on Sparklr.
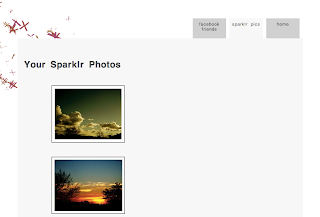
Ok, that is the functionality working. Now let’s see how it all happens under the hood.
When we visit the URL http://localhost:8080/tonr2/sparklr/photos by clicking on the tab, the request will arrive at the filter OAuth2ClientContextFilter which is defined by the xml namespaced element <oauth:client id="oauth2ClientFilter" /> in the spring-servlet.xml of the tonr project, which is referenced in the <http> element at the top of said file. Like this:
<http access-denied-page="/login.jsp?authorization_error=true" xmlns="http://www.springframework.org/schema/security">
<intercept-url pattern="/sparklr/**" access="ROLE_USER" />
<intercept-url pattern="/facebook/**" access="ROLE_USER" />
<intercept-url pattern="/**" access="IS_AUTHENTICATED_ANONYMOUSLY" />
<form-login authentication-failure-url="/login.jsp?authentication_error=true" default-target-url="/index.jsp"
login-page="/login.jsp" login-processing-url="/login.do" />
<logout logout-success-url="/index.jsp" logout-url="/logout.do" />
<anonymous />
<custom-filter ref="oauth2ClientFilter" after="EXCEPTION_TRANSLATION_FILTER" />
</http>
You can see that the access needed for accessing anything with the URL /sparklr/** requires a user with Role ROLE_USER. That means that when trying to access that URL before being logged in an AccessDeniedException will be thrown. The AccessDeniedException will be catched by the OAuth2ClientContextFilter which won’t do anything at all with this exception but rethrow it to be handled by the standard exception handling process of Spring Security.
The application is automatically redirected to the login.jsp.
After we login and still trying to reach the URL /sparklr/photos, the OAuth2ClientContextFilter is reached again. The request will get all the way through the SparklrServiceImpl which is the service in charge of reaching to Sparklr to retrieve the photos. This class will use a RestOperations instance (in particular an instance of OAuth2RestTemplate) to try to retrieve the photos from the remote Sparklr service using the following URL http://localhost:8080/sparklr2/photos?format=xml
This is what the OAuth2RestTemplate does internally when trying to contact the given URL:
This is what the OAuth2RestTemplate does internally when trying to contact the given URL:
It will first try to obtain the Access Token (in the form of an instance of OAuth2AccessToken) from the client context. In particular from the configured DefaultOAuth2ClientContext.
As we still don't have any access token for Sparklr, there is nothing stored on the DefaultOAuth2ClientContext. So the access token will be null at this point.
Next a new AccessTokenRequest will be obtained from the DefaultOAuth2ClientContext. The AccessTokenRequest and the DefaultOAuth2ClientContext are configured automatically by Spring at startup by the use of the namespaced bean definition <oauth:rest-template resource="sparklr" />. That definition will be parsed by the class RestTemplateBeanDefinitionParser.
Next as there is no access token on the context, an instance AccessTokenProvider will be used to try and retrieve the token. In particular an instance of AccessTokenProviderChain will be used. The AccessTokenProviderChain’s obtainAccessToken method will be called with the AccessTokenRequest and a AuthorizationCodeResourceDetails instance. This instance is configured by the resource attribute in the <oauth:rest-template> bean that references a <oauth:resource> element. Like this:
<oauth:resource id="sparklr" type="authorization_code" client-id="tonr" client-secret="secret"
access-token-uri="${accessTokenUri}" user-authorization-uri="${userAuthorizationUri}" scope="read,write" />
<oauth:rest-template resource="sparklr" />
The <oauth:resource> element will be parsed by the class ResourceBeanDefinitionParser at startup. In this particular case this will create an instance of the class AuthorizationCodeResourceDetails. In this instance, preconfigured client-id and client-secret will be set. Also configured in this instance are the required URLs for authenticating and requesting the Access Token.
The AccessTokenProviderChain’s obtainAccessToken method will go through the configured AccessTokenProvider instances to try and obtain the token. In the current example the only configured AccessTokenProvider is an instance of AuthorizationCodeAccessTokenProvider. This class will try to make a POST call to the URL http://localhost:8080/sparklr2/oauth/authorize to get the authorization code for this client/user.
The call to the /sparklr2/oauth/authorize endpoint will arrive on the FilterSecurityInterceptor for the Sparklr application. The interceptor will notice that the required URL requires a user with role ROLE_USER (in Sparklr) to be logged in to be able to access the contents from this endpoint. This is enforced by the following chunk of XML in the spring-servlet.xml of the Sparklr application (In particular look at the line that intercepts the URL “/oauth/**”):
<http access-denied-page="/login.jsp?authorization_error=true" disable-url-rewriting="true"
xmlns="http://www.springframework.org/schema/security">
<intercept-url pattern="/oauth/**" access="ROLE_USER" />
<intercept-url pattern="/**" access="IS_AUTHENTICATED_ANONYMOUSLY" />
<form-login authentication-failure-url="/login.jsp?authentication_error=true" default-target-url="/index.jsp"
login-page="/login.jsp" login-processing-url="/login.do" />
<logout logout-success-url="/index.jsp" logout-url="/logout.do" />
<anonymous />
</http>
When the interceptor realizes that the security constraint is not met, it will throw an AccessDeniedException. This exception will be picked up by the ExceptionTranslationFilter which will at the end of a couple more redirections, will redirect to the URL http://localhost:8080/sparklr2/login.jsp.
This redirect will be received by the AuthorizationCodeAccessTokenProvider in the Tonr application which will then throw the exception UserRedirectRequiredException. That exception will be then be captured by the Oauth2ClientContextFilter which will make the call to the redirect URL returned by Sparklr and adding the required extra parameters. Something like: http://localhost:8080/sparklr2/login.jsp?response_type=code&client_id=tonr&scope=read+write&state=dWby7l&redirect_uri=http%3A%2F%2Flocalhost%3A8080%2Ftonr2%2Fsparklr%2Fphotos
We are presented now with the login form for Sparklr. When we click on the login button, the following happens:
Username and password will be send to the URL /sparklr2/login.do. This URL is configured to be managed by the UsernamePasswordAuthenticationFilter when the attribute login-processing-url="/login.do" is configured on the <form-login> element. The UsernamePasswordAuthenticationFilter will extract the username and password from the request and will call the ProviderManager implementation of AuthenticationManager.
The AuthenticationManager will find the DaoAuthenticationProvider that is configured with in memory user details thanks to the XML element show next:
<authentication-manager alias="authenticationManager" xmlns="http://www.springframework.org/schema/security">
<authentication-provider>
<user-service id="userDetailsService">
<user name="marissa" password="koala" authorities="ROLE_USER" />
<user name="paul" password="emu" authorities="ROLE_USER" />
</user-service>
</authentication-provider>
</authentication-manager>
The DaoAuthenticationProvider will be able then to find the user marissa with the corresponding role ROLE_USER and authenticate her.
After succesfully authenticating in Sparklr, the framework redirects to the /sparklr2/oauth/authorize URL that was previously requested. This time access to the endpoint will be granted for the user that had just logged in.
The /oauth/authorize request in Sparklr is handled by the class org.springframework.security.oauth2.provider.endpoint.AuthorizationEndpoint that comes with the installation of the core Spring Security OAuth project. The use of this endpoint class is configured automatically when the following XML configuration is used:
<oauth:authorization-server client-details-service-ref="clientDetails" token-services-ref="tokenServices"
user-approval-handler-ref="userApprovalHandler">
<oauth:authorization-code />
<oauth:implicit />
<oauth:refresh-token />
<oauth:client-credentials />
<oauth:password />
</oauth:authorization-server>
When that xml element (<oauth:authorization-server> ) is used, many things happen when it is parsed by the class AuthorizationServerBeanDefinitionParser which is a complex parser that handles many different elements and options. Some of them we will see later, but for now we are only looking at the AuthorizationEndpoint.
The AuthorizationEndpoint maps the request /oauth/authorize as I have just said before. The first thing it will do is to check the kind of petition that the client is doing, basically looking at the request param response_type and checking if its value is either “code” or “token” to know if an authorization code or an access token is being requested. For the current call, the value of this parameter is “code” as you may remember.
The next thing that will happen is that the AuthorizationEndpoint will create an instance of org.springframework.security.oauth2.provider.AuthorizationRequest. The main part of the AuthorizationRequest, is the use of the clientId parameter to retrieve the client details of the connecting client. In this requets, the clientId is “tonr” and the details are retrieved from an InMemoryClientDetailsService that get configured by the XML element:
<oauth:client-details-service id="clientDetails">
<oauth:client client-id="my-trusted-client" authorized-grant-types="password,authorization_code,refresh_token,implicit"
authorities="ROLE_CLIENT, ROLE_TRUSTED_CLIENT" scope="read,write,trust" access-token-validity="60" />
<oauth:client client-id="my-trusted-client-with-secret" authorized-grant-types="password,authorization_code,refresh_token,implicit"
secret="somesecret" authorities="ROLE_CLIENT, ROLE_TRUSTED_CLIENT" />
<oauth:client client-id="my-client-with-secret" authorized-grant-types="client_credentials" authorities="ROLE_CLIENT"
scope="read" secret="secret" />
<oauth:client client-id="my-less-trusted-client" authorized-grant-types="authorization_code,implicit"
authorities="ROLE_CLIENT" />
<oauth:client client-id="my-less-trusted-autoapprove-client" authorized-grant-types="implicit"
authorities="ROLE_CLIENT" />
<oauth:client client-id="my-client-with-registered-redirect" authorized-grant-types="authorization_code,client_credentials"
authorities="ROLE_CLIENT" redirect-uri="http://anywhere?key=value" scope="read,trust" />
<oauth:client client-id="my-untrusted-client-with-registered-redirect" authorized-grant-types="authorization_code"
authorities="ROLE_CLIENT" redirect-uri="http://anywhere" scope="read" />
<oauth:client client-id="tonr" resource-ids="sparklr" authorized-grant-types="authorization_code,implicit"
authorities="ROLE_CLIENT" scope="read,write" secret="secret" />
</oauth:client-details-service>
As you can see in the XML chunk, “tonr” is configured as a client. When we retrieve the details of the client we get an instance of the ClientDetails object. ClientDetails source is shown next:
package org.springframework.security.oauth2.provider;
import java.io.Serializable;
import java.util.Collection;
import java.util.Map;
import java.util.Set;
import org.springframework.security.core.GrantedAuthority;
/**
* Client details for OAuth 2
*
* @author Ryan Heaton
*/
public interface ClientDetails extends Serializable {
/**
* The client id.
*
* @return The client id.
*/
String getClientId();
/**
* The resources that this client can access. Can be ignored by callers if empty.
*
* @return The resources of this client.
*/
Set<String> getResourceIds();
/**
* Whether a secret is required to authenticate this client.
*
* @return Whether a secret is required to authenticate this client.
*/
boolean isSecretRequired();
/**
* The client secret. Ignored if the {@link #isSecretRequired() secret isn't required}.
*
* @return The client secret.
*/
String getClientSecret();
/**
* Whether this client is limited to a specific scope. If false, the scope of the authentication request will be
* ignored.
*
* @return Whether this client is limited to a specific scope.
*/
boolean isScoped();
/**
* The scope of this client. Empty if the client isn't scoped.
*
* @return The scope of this client.
*/
Set<String> getScope();
/**
* The grant types for which this client is authorized.
*
* @return The grant types for which this client is authorized.
*/
Set<String> getAuthorizedGrantTypes();
/**
* The pre-defined redirect URI for this client to use during the "authorization_code" access grant. See OAuth spec,
* section 4.1.1.
*
* @return The pre-defined redirect URI for this client.
*/
Set<String> getRegisteredRedirectUri();
/**
* Get the authorities that are granted to the OAuth client. Note that these are NOT the authorities that are
* granted to the user with an authorized access token. Instead, these authorities are inherent to the client
* itself.
*
* @return The authorities.
*/
Collection<GrantedAuthority> getAuthorities();
/**
* The access token validity period for this client. Null if not set explicitly (implementations might use that fact
* to provide a default value for instance).
*
* @return the access token validity period
*/
Integer getAccessTokenValiditySeconds();
/**
* The refresh token validity period for this client. Zero or negative for default value set by token service.
*
* @return the refresh token validity period
*/
Integer getRefreshTokenValiditySeconds();
/**
* Additional information for this client, not neeed by the vanilla OAuth protocol but might be useful, for example,
* for storing descriptive information.
*
* @return a map of additional information
*/
Map<String, Object> getAdditionalInformation();
}
After the AuthorizationRequest object is created, it is checked to see if it has been approved. As it is just created, it has not been yet approved and the AuthorizationEndpoint will forward the request to the URL forward:/oauth/confirm_access which is internally configured by default in the framework.
The confirm_access URL needs to be handled in the application that we are using as authentication server, which is in this case is the Sparklr application. So in the Sparklr application the AccessConfirmationController is in charge of handling the request to the /oauth/confirm_access URL. It handles this URL by showing the page access_confirmation.jsp that contains the form for authorizing or denying access to the tonr client to the sparklr server
Now when you click on Authorize, the following happens:
A POST call is made to the URL /oauth/authorize in the Sparklr application. This call is handled by the class org.springframework.security.oauth2.provider.endpoint.AuthorizationEndpoint, in particular by the approveOrDeny method.
The approveOrDeny method will extract the AuthorizationRequest that is requesting access. The AuhtorizationRequest interface looks like:
package org.springframework.security.oauth2.provider;
import java.util.Collection;
import java.util.Map;
import java.util.Set;
import org.springframework.security.core.GrantedAuthority;
/**
* Base class representing a request for authorization. There are convenience methods for the well-known properties
* required by the OAUth2 spec, and a set of generic authorizationParameters to allow for extensions.
*
* @author Ryan Heaton
* @author Dave Syer
* @author Amanda Anganes
*/
public interface AuthorizationRequest {
public static final String CLIENT_ID = "client_id";
public static final String STATE = "state";
public static final String SCOPE = "scope";
public static final String REDIRECT_URI = "redirect_uri";
public static final String RESPONSE_TYPE = "response_type";
public static final String USER_OAUTH_APPROVAL = "user_oauth_approval";
public Map<String, String> getAuthorizationParameters();
public Map<String, String> getApprovalParameters();
public String getClientId();
public Set<String> getScope();
public Set<String> getResourceIds();
public Collection<GrantedAuthority> getAuthorities();
public boolean isApproved();
public boolean isDenied();
public String getState();
public String getRedirectUri();
public Set<String> getResponseTypes();
}
The redirectUri is extracted and the approval process is evaluated again, this time approving the AuthorizationRequest.
The request is also evaluated to make sure it is requesting the authorization code (by calling the method getResponseTypes on the AuthorizationRequest) and not the token. The framework will generate a new authorization code as requested. Then the approveOrDeny method will finish its work by returning a new instance of RedirectView that will be handled as a redirection back to the tonr application. In particular to the URL http://localhost:8080/tonr2/sparklr/photos;jsessionid=03B2E814391E010B3D1210241ECF6C0A?code=vqMbuf&state=aTSlVl in my current example.
The redirect arrives back on Tonr. Now Tonr will process the URL again, but this time it will try to obtain the access token in order to continue with the processing. As before, Tonr will use the OAuth2RestTemplate in combination with the AuthorizationCodeAccessTokenProvider to try and retrieve the access token from Sparklr. In particular they will make a request to the URL /sparklr/oauth/token with the parameters {grant_type=’authorization_code’, redirect_uri=’http://localhost:8080/tonr2/sparklr/photos’, code=xxxx
That call to Sparklr will be handled by the class org.springframework.security.oauth2.provider.endpoint.TokenEndpoint. This endpoint will create a new instance of OAuth2AccessToken and generate a response with that Bearer token.
Again Tonr receives this response and now tries again to make the call to Sparklr this time it will pass the Bearer access token, received in the previous step, as part of the Authorization header in the request.
That is all Sparklr needs to verify the request. The OAuth2AuthenticationProcessingFilter will extract the token from the request and with the help of the Oauth2AuthenticationManager will validate and authenticate the token.
When the token is verified, the call will finally arrive at the PhotoController which is in charge of serving the photos. Later in the week I will add a couple of UML diagrams that will help understand the relationship between the major classes involved in the OAuth for Spring Security project.
To understand the internal details of how the Spring Security framework work on the core you can check out the book 





