Last weekend I started working on my own in a small library for persisting java objects in different datasources and with different formats so that I was going to be able to leverage that library at work.
I intended to support different datasources. I started with MongoDB, Redis, File System, Cassandra, Riak and CouchDB.
The idea of the solution is to work as a kind of logger, so I took the main architecture characteristics from the Apache Log4j project. So for example I had the idea to easily plug the different datasources in what I called Appenders, following the Log4j concept.
Another thing I wanted is to be able to easily configure it with Spring, so I also created a small namespace for it.
The simple architecture I ended up with was something like this:
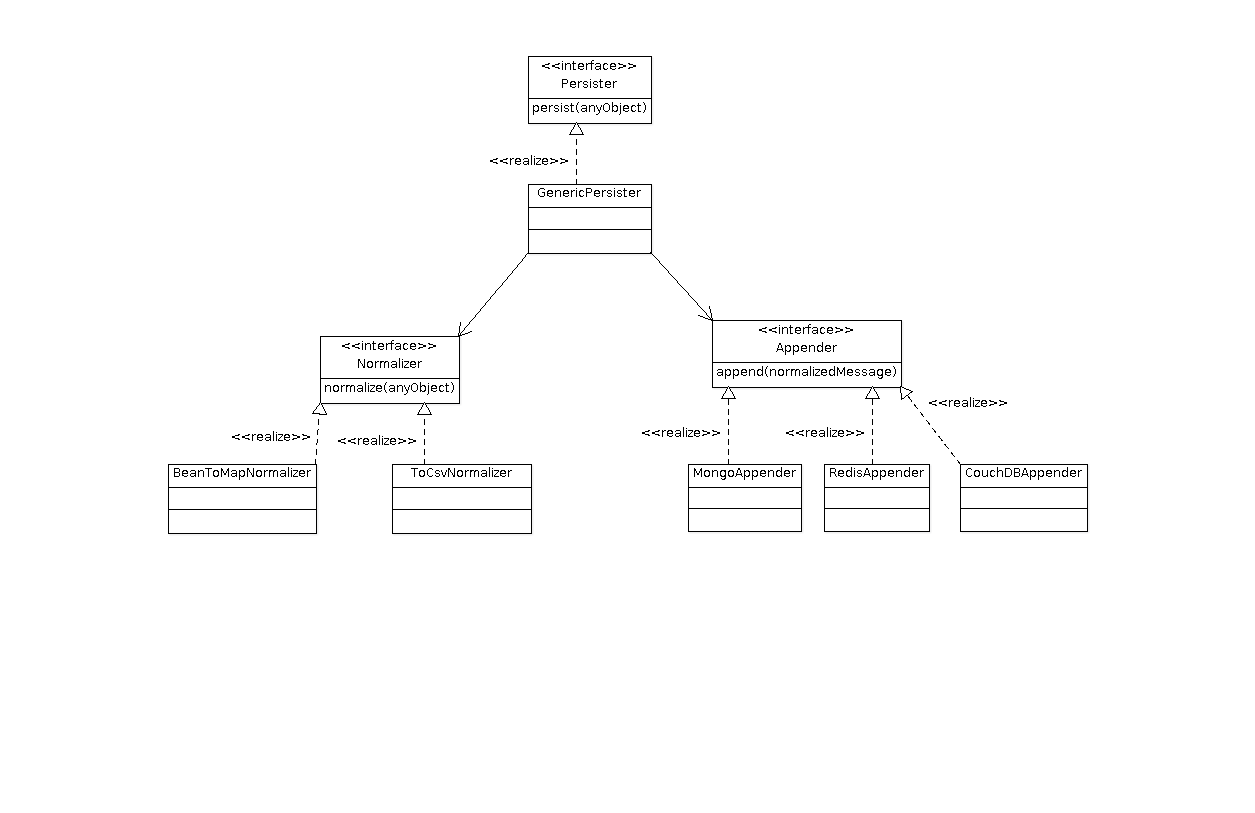
The idea is that any object will get “normalized” into a library internal object by using an implementation of a Normalizer. Then this normalized message goes to any of the Appenders where it gets converted into a provider specific message (e.g. DBObject in Mongo) then the appender takes care of storing it.
All the appenders and datastore libraries I currently use are very simple, and none of the datasources have been optimized anyhow, I work with them with their default installation behaviour.
If not for anything else, the library can at least serve to see the basic of how to interact with the different data sources. So next I show how all the appenders I have for the different Datasources.
package org.easytechs.recordpersister.appenders;
import com.mongodb.DB;
import com.mongodb.DBCollection;
import com.mongodb.DBObject;
import com.mongodb.Mongo;
public class MongoAppender extends AbstractAppender<DBObject>{
/**
*/
private DBCollection coll;
public MongoAppender(String host, String port, String dbName, String collection) throws Exception{
Mongo m = new Mongo(host , Integer.parseInt(port));
DB db = m.getDB(dbName);
coll = db.getCollection(collection);
}
@Override
public void close() {
}
@Override
protected void doAppend(DBObject record) throws Exception {
coll.insert(record);
}
}
package org.easytechs.recordpersister.appenders;
import org.easytechs.recordpersister.appenders.redis.KeyValue;
import redis.clients.jedis.Jedis;
public class RedisAppender extends AbstractAppender<KeyValue>{
/**
*/
private Jedis jedis;
public RedisAppender(String host) {
jedis = new Jedis(host);
jedis.connect();
}
@Override
public void close() {
jedis.disconnect();
}
@Override
protected void doAppend(KeyValue record) throws Exception {
jedis.rpush(record.getKey(), record.getValue());
}
}
package org.easytechs.recordpersister.appenders;
import java.util.Map;
import redis.clients.jedis.Jedis;
public class RedisHashAppender extends AbstractAppender<Map<String, String>> {
/**
*/
private String listKey;
/**
*/
private Jedis jedis;
public RedisHashAppender(String host, String listKey) {
this.listKey = listKey;
jedis = new Jedis(host);
jedis.connect();
}
@Override
public void close() {
jedis.disconnect();
}
@Override
protected void doAppend(Map<String, String> record) throws Exception {
String key = String.valueOf(record.hashCode());
for (String field : record.keySet()) {
jedis.hset(key, field, record.get(field));
}
jedis.rpush(getListKey(), key);
}
/**
* @return
*/
private String getListKey(){
return this.listKey;
}
}
package org.easytechs.recordpersister.appenders;
import org.easytechs.recordpersister.appenders.redis.KeyValue;
import com.basho.riak.client.IRiakClient;
import com.basho.riak.client.RiakFactory;
import com.basho.riak.client.bucket.Bucket;
public class RiakAppender extends AbstractAppender<KeyValue>{
private Bucket myBucket;
private IRiakClient riakClient;
public RiakAppender(String host, int port, String bucket) throws Exception{
riakClient = RiakFactory.pbcClient(host,port);
myBucket = riakClient.fetchBucket(bucket).execute();
}
@Override
public void close() {
riakClient.shutdown();
}
@Override
protected void doAppend(KeyValue record) throws Exception {
myBucket.store(record.getKey(), record.getValue()).execute();
}
}
package org.easytechs.recordpersister.appenders;
import java.util.Map;
import org.jcouchdb.db.Database;
public class CouchDBAppender extends AbstractAppender<Map<String, String>>{
private Database db;
public CouchDBAppender(String host, String database){
db = new Database(host, database);
}
@Override
public void close() {
}
@Override
protected void doAppend(Map<String, String> record) throws Exception {
db.createDocument(record);
}
}
package org.easytechs.recordpersister.appenders;
import java.nio.ByteBuffer;
import org.apache.cassandra.thrift.Cassandra;
import org.apache.cassandra.thrift.ColumnParent;
import org.apache.cassandra.thrift.ConsistencyLevel;
import org.apache.cassandra.thrift.TBinaryProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TFramedTransport;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.transport.TTransport;
import org.easytechs.recordpersister.appenders.cassandra.CassandraRow;
public class CassandraAppender extends AbstractAppender<CassandraRow>{
/**
*/
private Cassandra.Client client;
/**
*/
private ColumnParent columnParent ;
/**
*/
private TTransport tr;
private static final ConsistencyLevel CL = ConsistencyLevel.ANY;
public CassandraAppender(String host, int port, String keyspace, String columnParent) throws Exception{
tr = new TSocket(host, port);
TFramedTransport tf = new TFramedTransport(tr);
TProtocol proto = new TBinaryProtocol(tf);
client = new Cassandra.Client(proto);
tf.open();
client.set_keyspace(keyspace);
this.columnParent = new ColumnParent(columnParent);
}
@Override
public void close() {
tr.close();
}
@Override
protected void doAppend(CassandraRow record) throws Exception{
client.insert(ByteBuffer.wrap(record.getKey().getBytes()), columnParent, record.getColumns().get(0), CL);
}
}
import com.mongodb.DB;
import com.mongodb.DBCollection;
import com.mongodb.DBObject;
import com.mongodb.Mongo;
public class MongoAppender extends AbstractAppender<DBObject>{
/**
*/
private DBCollection coll;
public MongoAppender(String host, String port, String dbName, String collection) throws Exception{
Mongo m = new Mongo(host , Integer.parseInt(port));
DB db = m.getDB(dbName);
coll = db.getCollection(collection);
}
@Override
public void close() {
}
@Override
protected void doAppend(DBObject record) throws Exception {
coll.insert(record);
}
}
package org.easytechs.recordpersister.appenders;
import org.easytechs.recordpersister.appenders.redis.KeyValue;
import redis.clients.jedis.Jedis;
public class RedisAppender extends AbstractAppender<KeyValue>{
/**
*/
private Jedis jedis;
public RedisAppender(String host) {
jedis = new Jedis(host);
jedis.connect();
}
@Override
public void close() {
jedis.disconnect();
}
@Override
protected void doAppend(KeyValue record) throws Exception {
jedis.rpush(record.getKey(), record.getValue());
}
}
package org.easytechs.recordpersister.appenders;
import java.util.Map;
import redis.clients.jedis.Jedis;
public class RedisHashAppender extends AbstractAppender<Map<String, String>> {
/**
*/
private String listKey;
/**
*/
private Jedis jedis;
public RedisHashAppender(String host, String listKey) {
this.listKey = listKey;
jedis = new Jedis(host);
jedis.connect();
}
@Override
public void close() {
jedis.disconnect();
}
@Override
protected void doAppend(Map<String, String> record) throws Exception {
String key = String.valueOf(record.hashCode());
for (String field : record.keySet()) {
jedis.hset(key, field, record.get(field));
}
jedis.rpush(getListKey(), key);
}
/**
* @return
*/
private String getListKey(){
return this.listKey;
}
}
package org.easytechs.recordpersister.appenders;
import org.easytechs.recordpersister.appenders.redis.KeyValue;
import com.basho.riak.client.IRiakClient;
import com.basho.riak.client.RiakFactory;
import com.basho.riak.client.bucket.Bucket;
public class RiakAppender extends AbstractAppender<KeyValue>{
private Bucket myBucket;
private IRiakClient riakClient;
public RiakAppender(String host, int port, String bucket) throws Exception{
riakClient = RiakFactory.pbcClient(host,port);
myBucket = riakClient.fetchBucket(bucket).execute();
}
@Override
public void close() {
riakClient.shutdown();
}
@Override
protected void doAppend(KeyValue record) throws Exception {
myBucket.store(record.getKey(), record.getValue()).execute();
}
}
package org.easytechs.recordpersister.appenders;
import java.util.Map;
import org.jcouchdb.db.Database;
public class CouchDBAppender extends AbstractAppender<Map<String, String>>{
private Database db;
public CouchDBAppender(String host, String database){
db = new Database(host, database);
}
@Override
public void close() {
}
@Override
protected void doAppend(Map<String, String> record) throws Exception {
db.createDocument(record);
}
}
package org.easytechs.recordpersister.appenders;
import java.nio.ByteBuffer;
import org.apache.cassandra.thrift.Cassandra;
import org.apache.cassandra.thrift.ColumnParent;
import org.apache.cassandra.thrift.ConsistencyLevel;
import org.apache.cassandra.thrift.TBinaryProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TFramedTransport;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.transport.TTransport;
import org.easytechs.recordpersister.appenders.cassandra.CassandraRow;
public class CassandraAppender extends AbstractAppender<CassandraRow>{
/**
*/
private Cassandra.Client client;
/**
*/
private ColumnParent columnParent ;
/**
*/
private TTransport tr;
private static final ConsistencyLevel CL = ConsistencyLevel.ANY;
public CassandraAppender(String host, int port, String keyspace, String columnParent) throws Exception{
tr = new TSocket(host, port);
TFramedTransport tf = new TFramedTransport(tr);
TProtocol proto = new TBinaryProtocol(tf);
client = new Cassandra.Client(proto);
tf.open();
client.set_keyspace(keyspace);
this.columnParent = new ColumnParent(columnParent);
}
@Override
public void close() {
tr.close();
}
@Override
protected void doAppend(CassandraRow record) throws Exception{
client.insert(ByteBuffer.wrap(record.getKey().getBytes()), columnParent, record.getColumns().get(0), CL);
}
}
This is the abstract appender they all derive from:
package org.easytechs.recordpersister.appenders;
import java.util.ArrayList;
import java.util.List;
import org.easytechs.recordpersister.Appender;
import org.easytechs.recordpersister.NormalizedMessage;
import org.easytechs.recordpersister.RecordGenerator;
public abstract class AbstractAppender<T extends Object> implements Appender{
/**
*/
protected RecordGenerator<T> recordGenerator;
@Override
public void append(NormalizedMessage normalizedMessage) {
T record = recordGenerator.generate(normalizedMessage);
try{
doAppend(record);
}catch(Exception e){
e.printStackTrace();
//Anything else to do here???
}
}
@Override
public final void append(List<NormalizedMessage> messages){
List<T> records = new ArrayList<>();
for(NormalizedMessage message:messages){
records.add(recordGenerator.generate(message));
}
doBatchAppend(records);
}
/**
* Basic implementation. Override if the appender supports batch processing
* @param records
*/
protected void doBatchAppend(List<T> records){
for(T record:records){
try{
doAppend(record);
}catch(Exception e){
e.printStackTrace();
//Anything else to do here???
}
}
}
@Override
protected void finalize() throws Throwable {
super.finalize();
close();
}
protected abstract void doAppend(T record) throws Exception;
public void setRecordGenerator(RecordGenerator<T> recordGenerator){
this.recordGenerator = recordGenerator;
}
}
import java.util.ArrayList;
import java.util.List;
import org.easytechs.recordpersister.Appender;
import org.easytechs.recordpersister.NormalizedMessage;
import org.easytechs.recordpersister.RecordGenerator;
public abstract class AbstractAppender<T extends Object> implements Appender{
/**
*/
protected RecordGenerator<T> recordGenerator;
@Override
public void append(NormalizedMessage normalizedMessage) {
T record = recordGenerator.generate(normalizedMessage);
try{
doAppend(record);
}catch(Exception e){
e.printStackTrace();
//Anything else to do here???
}
}
@Override
public final void append(List<NormalizedMessage> messages){
List<T> records = new ArrayList<>();
for(NormalizedMessage message:messages){
records.add(recordGenerator.generate(message));
}
doBatchAppend(records);
}
/**
* Basic implementation. Override if the appender supports batch processing
* @param records
*/
protected void doBatchAppend(List<T> records){
for(T record:records){
try{
doAppend(record);
}catch(Exception e){
e.printStackTrace();
//Anything else to do here???
}
}
}
@Override
protected void finalize() throws Throwable {
super.finalize();
close();
}
protected abstract void doAppend(T record) throws Exception;
public void setRecordGenerator(RecordGenerator<T> recordGenerator){
this.recordGenerator = recordGenerator;
}
}
As an example of how the library would be used there are a couple of Tests. Like the following:
package org.easytechs.recordpersister;
import org.easytechs.recordpersister.GenericPersister;
import org.easytechs.recordpersister.appenders.MongoAppender;
import org.easytechs.recordpersister.normalizers.BeanToMapNormalizer;
import org.easytechs.recordpersister.recordgenerators.MongoDBFromMapGenerator;
import org.testng.annotations.BeforeMethod;
import org.testng.annotations.Test;
public class TestBeanMongoFullDocumentPersisterITest extends AbstractTimedTest{
/**
*/
private GenericPersister<TestBean> testObj;
@BeforeMethod
public void setup() throws Exception {
testObj = new GenericPersister<>();
MongoAppender appender = new MongoAppender("127.0.0.1", "27017", "test-db", "ticksfull2");
appender.setRecordGenerator(new MongoDBFromMapGenerator());
testObj.setNormalizedMessageTransformer(new BeanToMapNormalizer<TestBean>("symbol", "value","date"));
testObj.setAppender(appender);
}
@Test
public void shouldPersistOneItem() {
TestBean tick = new TestBean();
tick.setSymbol("XX");
tick.setValue("100.00");
tick.setDate(123444l);
testObj.persist(tick);
}
@Test(invocationCount=10)
public void shouldPersistManyItems() {
doTimed(new IndexedRunnable() {
@Override
public void run(int index) throws Exception {
TestBean tick = new TestBean();
tick.setSymbol("XX");
tick.setValue("100.00");
tick.setDate(123444l);
testObj.persist(tick);
}
}, 20000);
}
}
import org.easytechs.recordpersister.GenericPersister;
import org.easytechs.recordpersister.appenders.MongoAppender;
import org.easytechs.recordpersister.normalizers.BeanToMapNormalizer;
import org.easytechs.recordpersister.recordgenerators.MongoDBFromMapGenerator;
import org.testng.annotations.BeforeMethod;
import org.testng.annotations.Test;
public class TestBeanMongoFullDocumentPersisterITest extends AbstractTimedTest{
/**
*/
private GenericPersister<TestBean> testObj;
@BeforeMethod
public void setup() throws Exception {
testObj = new GenericPersister<>();
MongoAppender appender = new MongoAppender("127.0.0.1", "27017", "test-db", "ticksfull2");
appender.setRecordGenerator(new MongoDBFromMapGenerator());
testObj.setNormalizedMessageTransformer(new BeanToMapNormalizer<TestBean>("symbol", "value","date"));
testObj.setAppender(appender);
}
@Test
public void shouldPersistOneItem() {
TestBean tick = new TestBean();
tick.setSymbol("XX");
tick.setValue("100.00");
tick.setDate(123444l);
testObj.persist(tick);
}
@Test(invocationCount=10)
public void shouldPersistManyItems() {
doTimed(new IndexedRunnable() {
@Override
public void run(int index) throws Exception {
TestBean tick = new TestBean();
tick.setSymbol("XX");
tick.setValue("100.00");
tick.setDate(123444l);
testObj.persist(tick);
}
}, 20000);
}
}
If using from Spring, I’m developing a simple namespace so things like the following can be done:
<persister:mongo-document-persister id="persister" host="127.0.0.1" port="27017" db="test-db" collection="testcol" beanProperties="propA,propB,propC"/>
The Maven dependencies for all the drivers are:
<dependency>
<groupId>org.apache.cassandra</groupId>
<artifactId>cassandra-all</artifactId>
<version>1.0.10</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>com.basho.riak</groupId>
<artifactId>riak-client</artifactId>
<version>1.0.5</version>
</dependency>
<dependency>
<groupId>com.google.code.jcouchdb</groupId>
<artifactId>jcouchdb</artifactId>
<version>0.11.0-1</version>
</dependency>
<groupId>org.apache.cassandra</groupId>
<artifactId>cassandra-all</artifactId>
<version>1.0.10</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>com.basho.riak</groupId>
<artifactId>riak-client</artifactId>
<version>1.0.5</version>
</dependency>
<dependency>
<groupId>com.google.code.jcouchdb</groupId>
<artifactId>jcouchdb</artifactId>
<version>0.11.0-1</version>
</dependency>
The source code is in Github
Great books on NoSQL
No comments:
Post a Comment